分析带UMI标签的测序数据
分析带UMI标签的测序数据
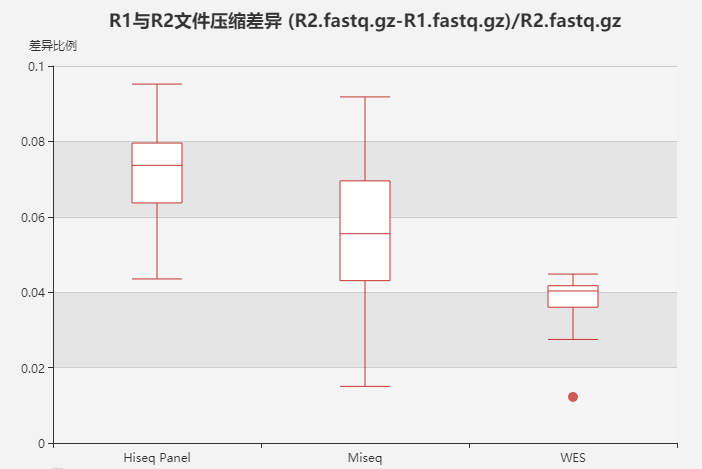
检测癌组织的低频突变,为了提高检测低频突变的灵敏度,往往进行高深度的测序。但样本之间存在交叉污染,测序有存在一定概率的错误,这些因素会导致高深度测序过程中将假阳性的信号放到,得到假阳性的结果。解决交叉污染的方法,有公司比如IDT采用唯一配对的样本index,只有配对的index中的reads才属于特定样本。解决测序错误的方法,研究人员在建库的时候,先对分子加上UMI碱基,unique molecular identifier -> UMI,然后根据来源于同一个分子的测序数据进行测序错误修正,得到正确的分子序列。两种方法结合可以减少交叉污染提高准确性(https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5759201/)。
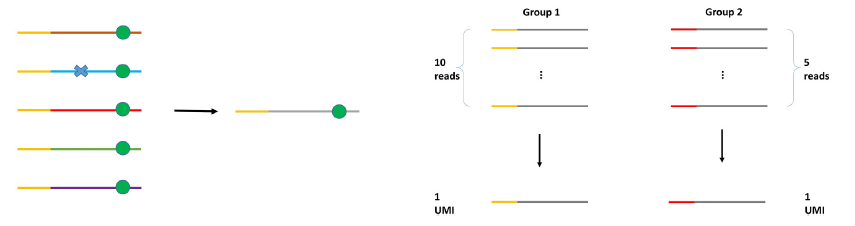
如图中所示,左侧一个分子被测了5次,其中第二次有一个测序错误,但该错误并没有在每个测序数据中出现,所以在后续合成一个分子的时候,测序错误被修正,只保留了真正的突变。(https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5852328/)
常规的肿瘤配对测序分析,或者遗传性突变位点的分析,并不需要UMI信息,所以包含UMI的数据分析是需要不一样的分析流程来得到准确的分析结果,其中包括提取UMI分子标签,合并来自同一个分子的测序reads,低频突变检测而非胚系突变检测等。
大致流程为: