
Ensemble Learning
文章目录
机器学习的目标是做预测,但有时候单个预测模型并不一定有很好性能。集成学习的思想是,把多个弱机器学习模型集成在一起,不同的学习方法之间可能相互补充,进而降低预测的错误率,提高最终的预测性能。集成学习在各个规模的数据集上都有很好的策略结果。
常见的集成方法有Bagging,Boosting,Stacking,Voting和Blending。
又可以分为两大类:(1)序列集成方法:其中参与训练的基础学习器按照顺序生成(Boost)。序列方法的原理是利用基础学习器之间的依赖关系。通过对之前训练中错误标记的样本赋值较高的权重,可以提高整体的预测效果。(2)并行集成方法,其中参与训练的基础学习器并行生成(如经典的Random Forest)。并行方法的原理是利用基础学习器之间的独立性,通过平均可以显著降低错误。
Bagging
套袋法,从训练集中随机抽取n个样本(样本被抽中的概率相同),训练得到一个模型,重复进行k轮可以得到k个训练集和k个模型,然后对这k个模型的结果进行aggregation得到最终预测结果。
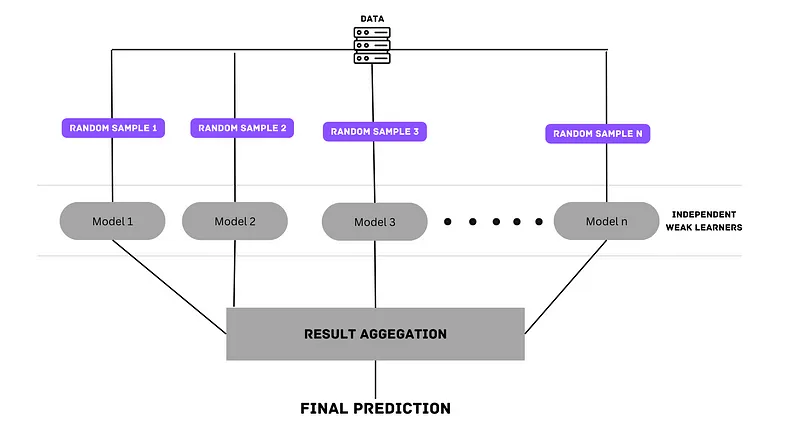
随机森林是最著名和最常用的模型之一,它使用 bagging 和特征随机性的概念来创建每个单独的树。 每个决策树都根据数据中的随机样本进行训练,然后进行aggregation。
Boosting
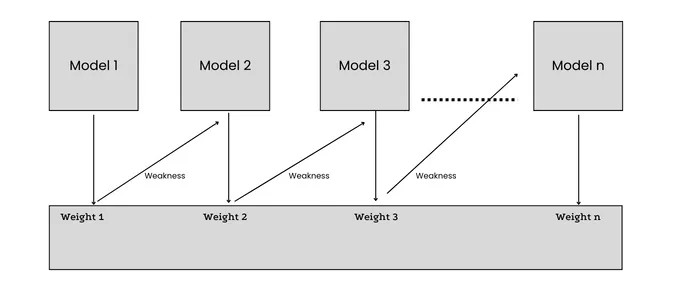
Bagging的基分类器训练是独立的,但boosting的训练依赖之前的模型,会根据错误率不断调整样本的权值,以顺序的方式实现同构ML算法,每个模型都试图通过减少前一个模型的误差来提高整个过程的稳定性,分类器也有权重调整,误差小的分类器权重大。
AdaBoost(Adaptive boosting)算法:刚开始训练时对每一个训练例赋相等的权重,然后用该算法对训练集训练t轮,每次训练后,对训练失败的训练例赋以较大的权重,也就是让学习算法在每次学习以后更注意学错的样本,从而得到多个预测函数。通过拟合残差的方式逐步减小残差,将每一步生成的模型叠加得到最终模型。
GBDT(Gradient Boost Decision Tree),每一次的计算是为了减少上一次的残差,GBDT在残差减少(负梯度)的方向上建立一个新的模型。
Bagging均匀取样,每个样本的权重相同,boosting的训练集不变,但样本的权重会不断调整,错误率越大的权重 越大,bagging的每个分类器可以并行生成,但boosting要顺序生成,因为后一个模型的参数更新需要前一轮模型的结果。
1)Bagging + 决策树 = 随机森林
2)AdaBoost + 决策树 = 提升树
3)Gradient Boosting + 决策树 = GBDT
Stacking
stacking技术是先用不同的机器学习模型对同一训练集进行学习,通过一个元(meta)分类器或者元(meta)回归器(meta classifier)来整合,stacking是对不同的机器学习模型进行整合。比如通过RF,GLM,DL等模型,对样本都有一个预测概率,然后将所有的预测概率当作样本的特征,用元分类器再学习一次。
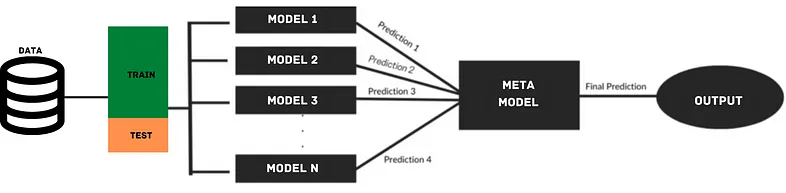
stacking使用交叉验证,分别将不同的部分数据作为验证集和训练集,测试集生成元特征时,需要用到k(k fold不是模型)个加权平均。
Blending
Blending 是另一种形式的集成学习技术,和stacking的区别是它使用来自训练集的 holdout作为验证集,将数据进行切割,验证集是不变的。Blending的好处就是训练时间缩短,缺点是学习的数据少,精度不如k-fold stacking。
Voting
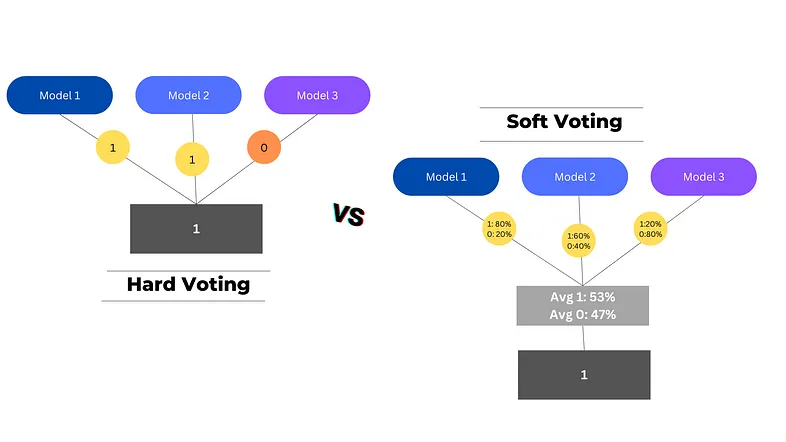
voting也是一种集成技术,在aggragation这一层实现。在voting中,多个基模型在整个数据集上进行训练以进行预测,每个基模型预测都被视为一次“投票”, 获得多数票的预测将被选为最终预测。Voting的感念和前面有重叠,但也不一样,比如stacking用的是meta classifier,meta classifier可以多种多样,但voting比较简单。voting又分为hard voting和soft voting。Hard Voting选择得票数最高的预测作为最终预测(根据分类的结果进行投票),而 Soft Voting 结合每个模型中每个类别的概率并选择概率最高的类别作为最终预测(整合分类的概率,有点像stacking中用glm作为meta classifier)。
参考
https://zhuanlan.zhihu.com/p/36848643
https://avoid.overfit.cn/post/f815d35fd51d44de8a17a3a5e609dfa6
https://zhuanlan.zhihu.com/p/36161812
https://zhuanlan.zhihu.com/p/126968534
https://baijiahao.baidu.com/s?id=1746006176040799612&wfr=spider&for=pc
https://www.cnblogs.com/zongfa/p/9304353.html
https://www.zhihu.com/question/29036379/answer/111637662
https://blog.csdn.net/ningyanggege/article/details/90642737
https://www.jianshu.com/p/4380cd1def76
####################################################################
#版权所有 转载请告知 版权归作者所有 如有侵权 一经发现 必将追究其法律责任
#Author: Jason
#####################################################################
文章作者 zzx
上次更新 2023-04-10