
cosine similarity
文章目录
在SNV分析中,我们在算signature和样本mutation spectrum之间的相似性时,会用到cosine similarity。cosine similarity (distance)的公式,其实就是两个向量的夹角的cosine值,计算公式如下

它与欧式距离的差别如下图,cosθ就是similarity,而d则是欧氏距离Euclidean distance。
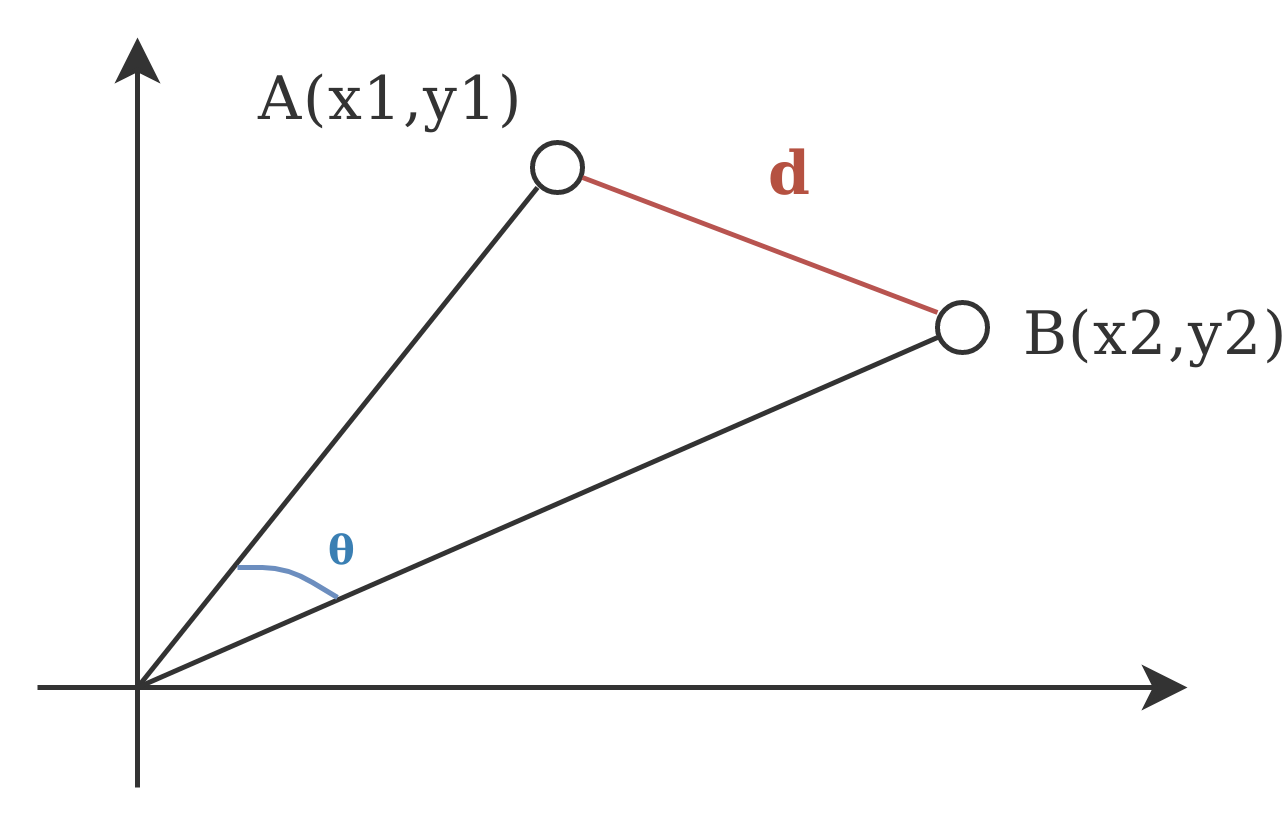
有些时候,距离也算作一种相似性,因为距离越远,说明两个样本越不相似。Euclidean distance和cosine similarity要根据情况来选择,最重要的是,是否要考虑weight or magnitude,参考下图。
在文本挖掘分析的时候,计算两个文本的相似性,我们可以统计每个词出现的次数,然后计算相似性(距离),因为文章有短有长,如果考虑单词出现的次数,那么字数多的文章一定与字数少的文章不一样(欧氏距离),所以如果我们不考虑这个量(magnitude)的时候,用cosine计算更加合适,结果也与欧氏距离不一样。

参考:
https://www.machinelearningplus.com/nlp/cosine-similarity/
#####################################################################
#版权所有 转载请告知 版权归作者所有 如有侵权 一经发现 必将追究其法律责任
#Author: Jason
#####################################################################
文章作者 zzx
上次更新 2020-06-17